「为什么有的 AI 拍照识别准、有的离谱?」
这是减脂用户最常问的技术问题之一。答案不在「用没用 AI」,而在用了什么 AI、怎么用、有没有兜底。
这篇我们公开小卡的完整识别架构。不是营销稿,是技术稿——希望你看完知道这件事到底难在哪、我们是怎么做的、哪些场景识别得好、哪些不行。
TL;DR
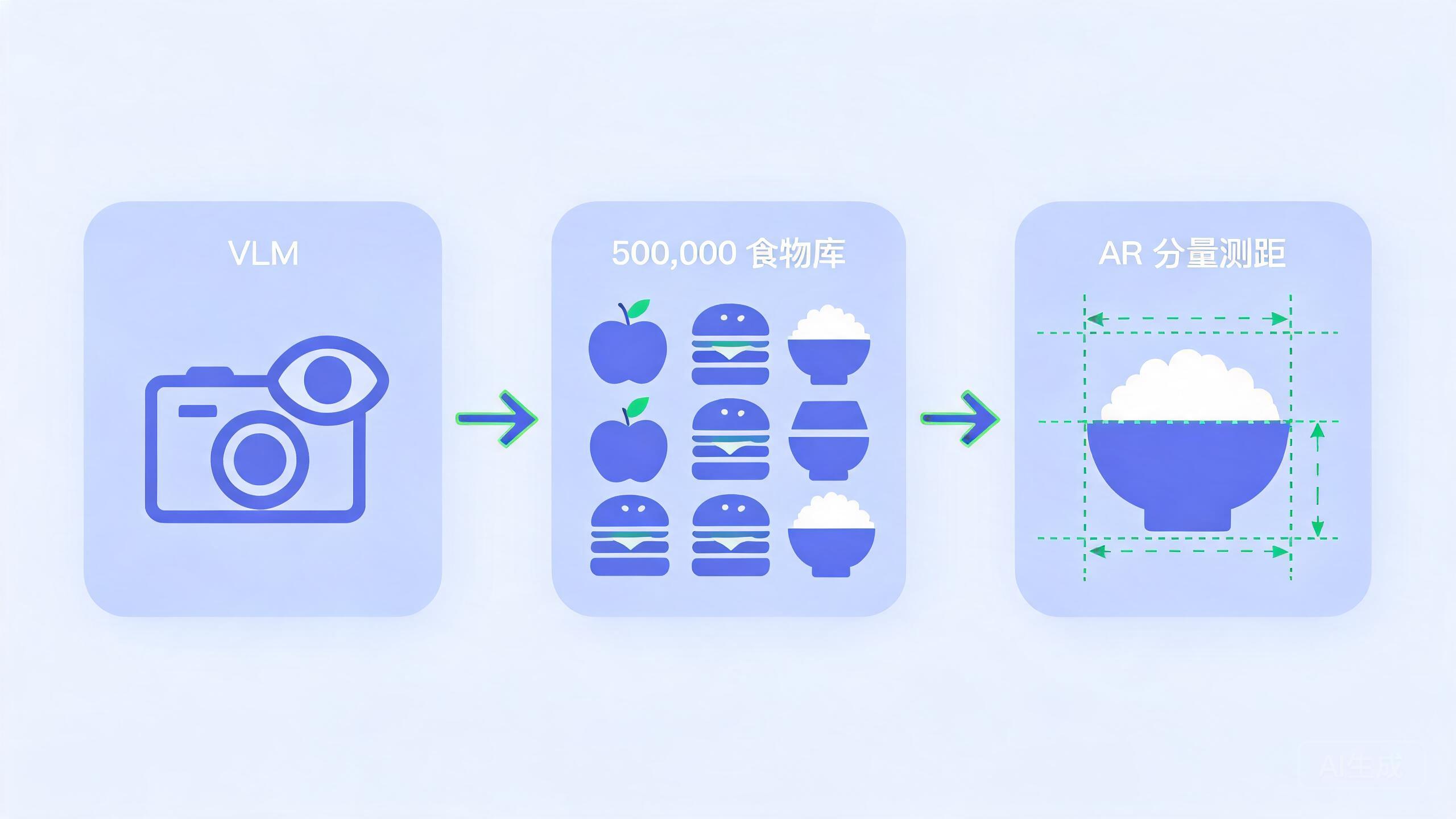
小卡的识别链路由三层构成,每一层各自承担不同任务:
| Layer | 模块 | 职责 | 输出 |
|---|---|---|---|
| 1 | 视觉大模型(VLM) | 看图、理解 | “这是一碗炒饭,带鸡蛋、青豆,白瓷碗装” |
| 2 | 50 万级中文食物数据库 | 营养匹配 | “炒饭(鸡蛋)每 100g = 175 kcal,蛋白质 4.6g…” |
| 3 | AR 分量测距 | 体积/重量估算 | “碗直径 14cm,推算饭体积 240ml ≈ 220g” |
三层串起来得出:这碗饭 ≈ 385 kcal,蛋白质 10g,碳水 64g,脂肪 8g。
为什么必须分层?直接喂 GPT 不行吗?
不行,有 3 个原因。
1. 通用大模型不懂中餐细节
ChatGPT、Claude 这类通用 VLM 是用全球图片训练的。它们识别披萨、汉堡、寿司很准,但识别夫妻肺片、东北锅包肉、酱香炒河粉、肥肠粉就开始迷糊。
中餐的「同一道菜,十八种做法」更是重灾区:红烧肉到底是上海做法(甜)还是湘菜做法(辣)?淮扬狮子头和川菜狮子头的油量完全不同。
通用模型只能给出「一道肉菜」这种粗描述。精准营养识别,必须有中文食物领域的专精数据。
2. 营养数据库的「真实数字」必须落在权威源上
VLM 可能识别出「这是炒饭」,但它给出的「热量大约 180 kcal/100g」是从哪来的?
如果让模型自己估,每次都会有 ±20% 漂移。同一道菜今天给 180 明天给 220,用户根本没法用。
营养数据必须严格落到真实文献:
- 中国营养学会《中国居民膳食指南(2022)》
- 《中国食物成分表(标准版第 6 版)》
- 《中国居民膳食营养素参考摄入量(2023 版)》
- 国家卫健委《食养指南》系列文件
这就是为什么我们建了 50 万级中文食物数据库,而不是依赖模型自己生成数字。
3. 「克数」是物理量,不是图像可识别属性
VLM 看图能识别「这是米饭」,但不能从二维图判断重量。
「一碗米饭」到底是 150g 还是 300g?差一倍。两个量识别成同一个,热量就差一倍。
这是行业里大部分拍照识别 App 的盲区——识别准,但份量靠**「一碗」「半碗」「一盘」**这种用户主观估计。结果是:数据库再准也白搭。
我们用 AR 深度感知 + 餐具基准比例,从图像直接算出体积。
三层架构深度展开
Layer 1 · 视觉大模型(VLM)
用途:做食物理解
输入:一张原始照片
输出:结构化的食物语义描述
{
"dish_name": "炒饭",
"ingredients": ["米饭", "鸡蛋", "青豆", "胡萝卜丁", "葱花"],
"cooking_method": "炒",
"container": "白瓷碗",
"estimated_oil_level": "中等",
"garnish": ["葱花"]
}
核心能力:不只是「这是什么」,而是「由哪几种食材组成、烹饪方式、配料、容器类型」。
为什么这步重要:
- 食材列表决定了营养匹配方向
- 烹饪方式决定了油脂含量(蒸 vs 炒 vs 炸 差 3 倍)
- 容器类型给 Layer 3 的体积测算提供参考基准
Layer 2 · 50 万级中文食物数据库
用途:精准营养匹配
输入:Layer 1 的食物语义描述
输出:候选食物条目 + 完整营养数据
数据库结构示例(简化版):
食物 ID:#82743
中文名:鸡蛋炒饭(家常版)
英文名:Egg Fried Rice (homestyle)
能量:175 kcal/100g
蛋白质:4.6g/100g
脂肪:6.2g/100g
碳水化合物:24.3g/100g
膳食纤维:0.8g/100g
钠:280mg/100g
依据文献:中国食物成分表第 6 版 + 中国居民膳食指南 2022 烹饪油参数
同热量参照:≈ 1.2 只苹果 / 0.7 碗白米饭
覆盖范围(从 intro 摘):
- 中式家常 + 八大菜系(川 / 粤 / 东北 / 淮扬 / 湘 / 闽 / 徽 / 鲁)
- 主流外卖品类(奶茶 / 咖啡 / 汉堡 / 披萨 / 烧烤 / 便当 / 轻食沙拉 / 米线 / 麻辣烫)
- 连锁餐饮品牌(星巴克 / 肯德基 / 麦当劳 / 海底捞 / 瑞幸 / 喜茶 / 奈雪 / Manner / 霸王茶姬 等)
- 包装食品(条码扫描覆盖国内主流商超大量 SKU)
- 食材原料(蔬菜 / 肉类 / 海鲜 / 水果 / 坚果 / 调味料 / 谷物 / 豆制品)
由专业营养师团队每周维护更新。
Layer 3 · AR 分量测距
用途:从图像估算食物体积和重量
核心技术:
- AR 深度感知:利用手机摄像头 + 测距传感器(LiDAR 等)获取三维深度信息
- 平面识别:识别桌面 / 托盘平面作为基准
- 餐具基准比例:数据库里有常见碗 / 盘 / 杯子的标准尺寸,通过相对比例反推食物体积
- 食物体积模型:针对不同食物形态(米饭 = 圆顶 / 汤 = 圆柱 / 菜 = 不规则)用不同体积公式
输出:
食物体积:240 ml
推算重量:220 g(基于食物密度 0.91)
置信度:0.78
置信度低于 0.5 时,UI 会提示用户:「光线 / 角度可能影响识别,建议俯拍 + 完整餐具入镜」。
三层串起来
照片 → VLM → {dish: "炒饭", ingredients: [...], container: "白瓷碗"}
↓
数据库匹配 → {kcal/100g: 175, protein: 4.6g, ...}
↓
AR 测距 → {volume: 240ml, weight: 220g}
↓
最终结果:385 kcal · 蛋白质 10g · 碳水 64g · 脂肪 8g
局限与边界(诚实说)
技术不是万能的。这是我们真实知道的局限:
1. 重叠摆盘准确率会掉
火锅 / 拼盘 / 自助餐这种「菜叠菜」的场景,Layer 1 的食材识别会漏掉一部分被遮挡的菜。我们的解法是:支持用户手动追加食材(比如点选已识别食材后追加)。
2. 隐形热量无法识别
菜里有多少油?多少糖?多少酱?这些从图像看不出来,只能靠数据库的「家常油量」预设值。
如果你家做菜放油特别少(或特别多),识别结果会有 ±15% 偏差。我们的建议:用一周数据,自己感觉哪些菜识别偏低,做手动校准。
3. 极小份量的精度有限
AR 测距对体积 > 50 ml 的食物比较准,小于这个数的精度会下降(比如一勺酱、一小块糖)。这类食物建议用条码或搜索方式记录。
4. 异形容器的体积假设可能错
如果你用的是非标准餐具(比如手工窑变碗 / 奇怪形状的便当盒),AR 测距的基准比例会出偏差。这种情况建议先在 App 里录一次该容器的尺寸,之后就准了。
行业对比(为什么三层都重要)
我们对比过几款主流热量计算 App 的识别能力(详见 热量计算 App 哪个最准),典型情况:
| App | Layer 1(VLM) | Layer 2(中文数据库) | Layer 3(份量测算) | 实测准确率 |
|---|---|---|---|---|
| 小卡 | ✅ 中餐专精 | ✅ 50 万级 + 4 文献 | ✅ AR 测距 | 85% |
| 薄荷健康 | ⚠️ 通用 | ✅ 100 万级(国内最大) | ⚠️ 用户手输份量 | 60% |
| Keep | ⚠️ 通用 | ⚠️ 偏运动场景 | ❌ 无 | 45% |
| FatSecret | ⚠️ 国际化 | ❌ 中餐弱 | ⚠️ 用户手输份量 | 50% |
核心结论:即使数据库再大(薄荷的 100 万 vs 小卡的 50 万),没有 AR 测距,份量靠用户主观估,准确率必然有上限。
FAQ
Q1. AR 测距需要 iPhone 自带 LiDAR 吗?
有 LiDAR 的 iPhone Pro 系列效果最好(测距更准)。没有 LiDAR 的设备(普通 iPhone / Android)会回退到「视觉深度估算」+「餐具基准比例」,准确率略低但仍可用。
Q2. 识别错了能改吗?
当然。所有识别结果都可以手动调整食材、克数、热量、烹饪方式。我们建议:AI 识别完后只调整明显错的,小偏差不用纠结(周平均比单餐准)。
Q3. 数据库会不断更新吗?
会。营养师团队每周维护:
- 新增连锁品牌产品(比如瑞幸新出的咖啡)
- 新增节令食物(立冬的火锅 / 中秋的月饼)
- 更新营养数据(随着膳食指南版本更新)
Q4. 我自己做的「特殊菜」怎么办?
支持自定义食物:输入食材列表 + 克数,系统按食物成分表自动算出营养,长期记录后就能像识别外食一样直接复用。
Q5. 模型会不会收集我的食物照片?
不会。识别完成后,原始照片仅保存在你设备本地,可以选择是否上传云端备份(完全用户可控)。详见我们的隐私政策。
Q6. 为什么不直接用 OpenAI / Anthropic 的 API?
商业模型(GPT / Claude)在中餐识别上表现一般,而且对接 API 也意味着每次识别都要把用户的食物照片传给第三方。我们选择自训练的中文 VLM + 私有数据库,数据不出域。
最后
「AI 拍照识别」听起来像一句营销话术,但展开之后是视觉大模型 + 营养数据库 + AR 测距三件具体的工程活。
少一层都不行。
如果你想体验这套架构,小卡健康 iOS 和 Android 都可以免费下载,新用户均有免费试用次数。
更多技术细节看 科学方法论页,包括公式来源和 AI 搭子的模型架构。
有想看的技术展开?告诉我们:miaoyancontact2024@gmail.com